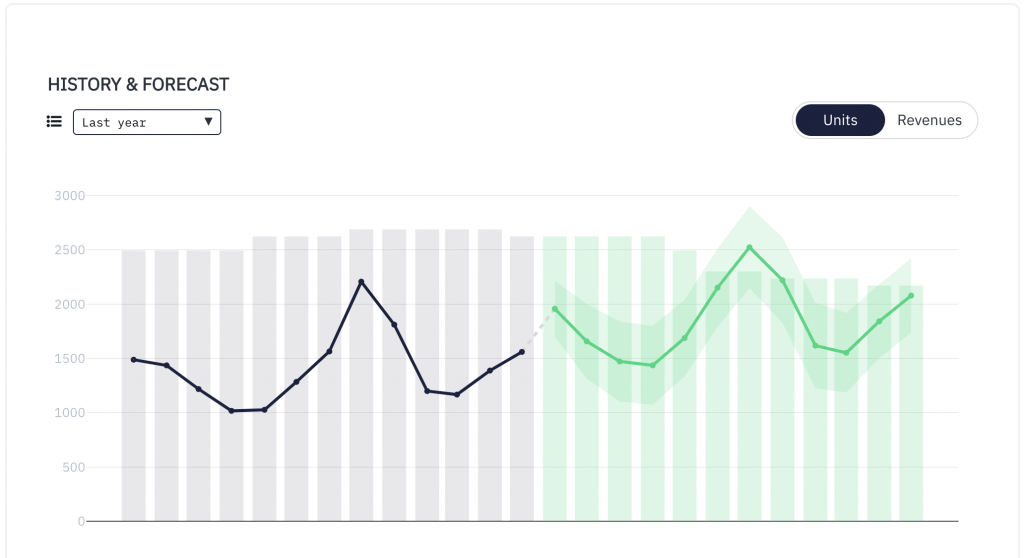

Every empty shelf in a store represents a lost sale and a disappointed customer. On the other hand, every overstocked warehouse is a black hole for capital, tying up funds in products that aren’t selling. This constant balancing act between having too much or not enough is one of the most fundamental challenges in business. So how do you find the right balance? Getting it right isn’t about luck; it’s about planning ahead strategically. Demand forecasting is a critical process that allows companies to navigate this challenge by turning historical data and market signals into a clear vision of future sales that leads to smarter, more profitable decisions.
What Is Demand Forecasting?
Demand forecasting, at its core, is the process of using predictive analysis and historical data to estimate future customer demand for a product or service.
The primary objective of demand forecasting is to make reliable predictions that can guide every decision from inventory control to marketing spend. It’s important not to confuse demand forecasting with demand planning. Forecasting is the predictive step, the act of generating the numbers. Demand planning is what comes after that. Demand planning uses the forecast to organize and execute actions across the entire supply chain, such as managing inventory levels, scheduling production, and planning logistics. One predicts the future, then the other prepares for it.
Why Demand Forecasting Is Crucial for Business Success
Accurate demand forecasting is a powerful driver of business performance. The impact of forecasting is felt across the entire organization. It leads directly to optimized inventory management, preventing both costly stockouts and the excess inventory that inflates carrying costs. If you have a reliable picture of future sales, you can also achieve much stronger financial planning and budgeting. Revenue projections become more dependable, making it easier to allocate resources effectively. This accuracy ripples through the supply chain and creates enhanced efficiency from the procurement of raw materials to the final delivery of goods. By consistently meeting customer needs without wasting resources, businesses can significantly boost customer satisfaction and build lasting loyalty which is invaluable.
Types of Demand Forecasting
Demand forecasts can be classified in several ways depending on their scope, timeframe, and the methodology used. The following categories are not mutually exclusive. In fact, a sophisticated business will likely use a combination of different forecast types to meet specific objectives.
Short-Term vs. Long-Term Forecasting
The most common distinction between short-term and long-term forecasting is based on the timeframe. Short-term forecasting typically looks ahead for a period of three to twelve months. It’s tactical, informing immediate operational decisions like managing inventory levels for the next quarter, creating production schedules, and allocating staff. Long-term forecasting extends beyond a year as its focus is strategic. This type of forecast is used to make major business decisions, including capacity planning for a new factory, exploring market expansion, and securing long-term financial arrangements.
Macro-Level vs. Micro-Level Forecasting
Forecasts can also be differentiated by their level of aggregation. Macro-level forecasting takes a wide-angle view by analyzing broad economic conditions, overarching industry trends, and the general market landscape. The goal here is to understand the external forces that will shape the business environment. Micro-level forecasting is far more granular. It zeroes in on specifics like the demand for a single product, the sales projections for one business unit, or the expected foot traffic at an individual store, guiding very precise decisions.
Active vs. Passive Forecasting
The approach to forecasting often depends on a company’s own market strategy. Passive forecasting is built on the assumption that future demand will largely follow historical patterns. This method is often suitable for stable, established businesses that experience consistent and predictable growth. Active forecasting is used when a company’s own actions are expected to significantly influence future demand. This is essential when planning for marketing campaigns, major promotions, significant pricing changes, or new product launches that will actively shape market response.
Key Demand Forecasting Methods
Businesses have a variety of techniques at their disposal to create forecasts. The choice of method is never random as it depends on critical factors such as the availability and quality of historical data, the desired level of accuracy, and the unique characteristics of the product or market. Understanding the following main approaches is the first step toward selecting the right tool for the job.
Qualitative Methods
When historical data is scarce, unreliable, or simply irrelevant (as is the case with a groundbreaking new product), businesses turn to qualitative methods. These techniques are subjective, relying on expert opinion, judgment, and market intelligence to build a picture of the future. Common examples include the Delphi method, which involves polling a panel of experts through multiple rounds to reach a consensus. Other approaches involve structured market research, such as customer surveys and focus groups, or creating a sales force composite, where insights are gathered directly from the sales team who have their finger on the pulse of the customer base.
Quantitative Methods
The most common approach, especially in data-rich environments, is the use of quantitative methods. These techniques leverage historical numerical data to make statistical projections about the future. Within this category, two main types stand out. Time series analysis examines past data patterns to predict future ones, using models like moving averages and exponential smoothing to identify trends and seasonality. The second type, causal models, goes a step further by identifying the statistical relationships between demand and other variables. A technique like regression analysis, for example, can determine how factors such as price, advertising spend, or a competitor’s actions impact sales.
The Demand Forecasting Process: A Step-by-Step Guide
Implementing demand forecasting is not a one-time task but a cyclical and iterative process. Its implementation begins with setting clear objectives to define precisely what needs to be forecast and for what purpose.
The next crucial step is data collection and cleaning. This involves gathering all relevant historical sales data, as well as information on external factors, and ensuring it is accurate and complete.
Then with a clean dataset, the team can move on to selecting the right model. This means choosing a qualitative or quantitative method that aligns with the business objective and the nature of the data.
Once a model is chosen, the next step is generating the forecast by running the analysis and creating the projections. But the process doesn’t end there. The final, ongoing step is to validate and refine the forecast by measuring its accuracy against actual results and using that feedback to adjust and improve the model for future use.
Tools and Technology for Modern Forecasting
A wide range of tools are available to support the demand forecasting process, catering to different levels of complexity and scale. For simple models and smaller datasets, basic spreadsheets like Excel or Google Sheets can be surprisingly effective. However, as analytical needs grow, many businesses turn to dedicated statistical software like R and Python, which offer powerful libraries for running more complex quantitative analyses. Further up the ladder are integrated business platforms, such as Enterprise Resource Planning (ERP) and Supply Chain Management (SCM) systems. These often have built-in forecasting modules that connect predictions directly to inventory and production planning. At the cutting edge are dedicated AI-powered forecasting platforms that leverage machine learning to analyze vast datasets, identify complex patterns, and deliver a superior level of accuracy.
How to Calculate Demand Forecasting with AI
Quantitative and qualitative forecasting, as well as causal factors analysis, all play a fundamental role when it comes to calculating predictions and implementing the planning process. Advanced demand planning tools like Intuendi rely on a mix of best-in-class technologies and deep knowledge of processes to packaging solutions that deliver value and results to clients.
What really sets a solution like Intuendi apart from traditional tools is the ability to leverage AI to compute a more accurate and informed forecast. Mastering the state of the art of Time Series Analysis techniques, including the capability to add sophistication to even the simplest of algorithms, and developing -through the years- the AI that is required to decide which one should be used to forecast a new or existing product or sales channel, is the foundation of a modern data-driven planning process. An accurate forecast can serve as a great starting point, but you can’t implement a successful demand planning routine without real-time visibility of products’ stockout and understocking risks. That’s, again, where AI comes into play: the ability to identify product classes, trends and seasonality patterns, as well as analyses of the impact of the external context on future demand helps compute not only better predictions, but empowers sales and operations teams with the right timing to make the best decisions with the lowest risks.
Long story short, AI-driven products like Intuendi compute forecasts that deliver accuracy, great-timing, and reliable results. Contact us today for a free deep dive into AI demand forecasting.
Example of Demand Forecasting
ACME trading company wishes to improve their efficiency in its procurement and supply process, so they decided to apply demand forecasting techniques to their business.
Following the above steps they first of all defined their objectives: reduce stockouts while maintaining a lean inventory. Within their ERP system, their sales history for the last three years was well recorded and used this data to forecast their demand. By analysing this data they discovered trends, seasonalities and patterns in their sales and so began adjusting and planning their procurement of goods to match this demand. The result of course was a drastic reduction in stockouts against only a slight increase in the average inventory value during the peak season.
Common Challenges and How to Overcome Them
Even with the best tools, it’s normal for companies to face common obstacles in achieving accurate forecasts. One of the most frequent obstacles is poor data quality or simply having insufficient historical data to work with. The solution here is implementing rigorous data cleaning processes and, where data is lacking, supplementing quantitative methods with qualitative insights.
Another common obstacle is accounting for market volatility and unexpected external events, like an economic downturn or supply chain disruption. While impossible to predict perfectly, using scenario planning can help businesses prepare for a range of potential futures.
Finally, many companies struggle with misinterpreting seasonality and underlying trends. This issue can often be mitigated by carefully choosing the right statistical model that is designed to identify and properly account for these specific patterns.
Best Practices for Accurate Demand Forecasting
Improving forecast accuracy is an ongoing commitment, not a one-time implementation. Success hinges on a few core principles. It is essential to regularly update and review forecasts, as market conditions are never static. The most effective forecasting processes also rely on cross-departmental collaboration, ensuring that valuable insights from sales, marketing, and finance are integrated into the analysis. This creates a holistic view that is far building resilience into the processmore robust than any single department’s perspective. Finally, by using sensitivity analysis and scenario planning is key. Understanding potential outcomes under different conditions allows a business not only to react to change but to prepare for it proactively.
