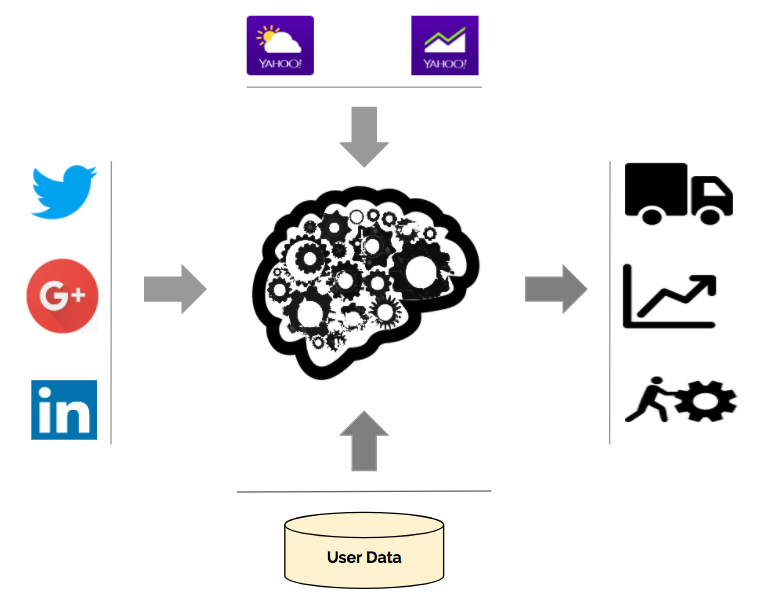
If you read the articles Advanced time series methods for sales forecasting or Basic time series methods for sales forecasting, you know that there exist several methods for demand forecasting.
As you know, those models use a historical representation of a product through time series. The most important issue is that numbers, if not helped, are apathetic.
In fact, are we sure that, given the same historical data, fashion products will have the same future behaviour as the smartphones?
Obviously not. In fact, there are some kinds of external and heterogeneous (exogenous) data which can be considered for improving our forecast. Facebook likes or Twitter trends can be analyzed in order to understand the sentiment about a certain topic. The process of understanding the relationship between the natural language and the related topic is called Sentiment Analysis. Furthermore, exogenous data like weather forecasts may be combined with the historical data in order to give a better representation of the past.
However, how can we exploit exogenous variables for a proper forecasting? Let us make a simple example.
Suppose you sell ice-creams and you have to forecast the demand for the next month in order to buy the right quantity of raw materials. Suppose to have at your disposal the forecast of the mean temperature (degrees) for the next month. If you collected such information during all your history, then you can find a relationship between the temperature and the ice-creams demand.
Let us make a numerical example. Suppose you have a three months history with the associated forecasts of the mean temperature.
| Month | March | April | May | June |
| Sales | 30 | 40 | 50 | ? |
| Temperature forecast | 20 | 25 | 26 | 35 |
If you do not consider the temperature, you probably forecast 60 sales for June. On the contrary, considering also the temperature data, solving a simple least squares problem you forecast 72 sales for June, which seems to be a more appropriate forecast, due to the very high temperature.
In conclusion, we can say that, probably, the hardest part of this process is to find the proper data sources in a way such that they can be included in a training process for a Machine Learning model for example.